
B-tree 가 무엇일까?
데이터베이스의 인덱스를 구성하기 위한 대표적인 알고리즘은 바로 B-tree 이다.
B-tree 가 뭔지 알기 위해 구글 검색을 해보면 한국어로 된 웹페이지들이 조금 나오긴 하는데, 사이트마다 설명도 조금씩 다르고 잘못 설명하는 곳도 있었고, 무엇보다 정확한 알고리즘을 설명한 곳이 없어서 이해하기가 어려웠다. 그래서 Wikipedia 에서 찾아봤는데, 오히려 여기에 제일 잘 설명이 된 것 같아 한글로 번역을 해보았다.
번역한 사이트는 Wikipedia B-tree 이다. 번역하고 나서 보니 불필요한 내용도 많았다. B-tree 가 뭔지 알려면 개요, 기술적 설명, 알고리즘 부분만 읽어보면 될 것 같다.
그 후에 여기를 보면 코드와 함께 더 자세히 설명되어 있어서 이해하기 좋다.
이제부터 아래 내용은 번역된 내용이다.
Binary tree와 헷갈리지 말자.
뒤에 나오겠지만, balanced tree도 아니다. 많은 블로그에서 잘못 소개하고 있는데, self-balancing tree 의 한 종류로 B-tree 가 있는 것이다.
| B-tree | |
| 알고리즘 종류 | 트리 |
| 발명시기 | 1971년도 |
| 발명자 | Rudolf Bayer, Edward M. McCreight |
| 알고리즘 | 평균 시간복잡도 | 최악 시간복잡도 |
| 공간 | O(n) | O(n) |
| 탐색 | O(log n) | O(log n) |
| 삽입 | O(log n) | O(log n) |
| 삭제 | O(log n) | O(log n) |
B-tree 는 self-balancing tree 자료구조로서, 데이터를 정렬된 순서로 유지하면서 검색, 순차접근, 삽입, 삭제 모두 시간복잡도 O(log n) 으로 수행할 수 있다.
B-tree 는 binary search tree 의 일반화된 버전으로서, binary search tree 는 자식노드를 2개만 가지는 것에 비해 B-tree 는 2개 이상을 가질 수 있다.
Self-balancing binary search tree 와는 다르게, B-tree 는 많은 블럭으로 구성된 큰 규모의 데이터의 읽고 쓰기에 최적화되어있다. 외부 메모리를 위한 데이터구조로서 적합하다. 그래서 보통 데이터베이스와 파일시스템의 자료구조로서 사용된다.
개요
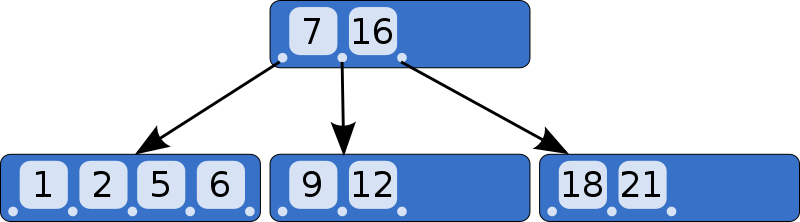
B-tree 에서는 리프노드를 제외한 내부노드에서 미리 정해진 개수 내에서 여러 자식노드를 가질 수 있다. 그리고 데이터가 삽입되거나 삭제될 때 자식노드의 수가 변한다. 또한 미리 정해진 자식노드의 개수를 유지하기 위해, 내부노드끼리 서로 합쳐지거나 분리될 수도 있다.
자식노드들의 개수가 범위 내에서 변할 수 있기 때문에, B-tree 는 다른 self-balancing search tree 에 비해서 리밸런싱하는 횟수가 적지만, 비어있는 곳이 존재하기 때문에 공간적인 면에서는 손해가 있다.
자식노드들의 개수의 범위는 보통 구현하면서 고정된 숫자로 정한다. 예를 들어 2-3 B-tree는 내부노드가 2개 또는 3개의 자식노드만 가질 수 있게 한다.
B-tree 의 각 내부노드들은 몇 가지의 키를 가지고 있다. 이 키들은 서브트리를 나누는 기준이 된다. 예를 들어 내부노드가 3개의 자식노드(또는 서브트리)를 가지고 있다면, 이 내부노드는 2개의 키(a1, a2)를 가지고 있다. 왼쪽에 있는 서브트리에 속한 모든 노드가 가지고 있는 키는 a1 보다 작은 값을 가지고 있다. 가운데 있는 서브트리에 속한 모든 노드에 속한 모든 노드가 가지고 있는 키는 a1 과 a2 사이에 있고, 오른쪽에 있는 서브트리에 속한 모든 노드가 가지고 있는 키는 a2 보다 큰 값을 가지고 있다.
일반적으로 한 노드가 가질 수 있는 키의 개수는 d 와 2d 사이의 값으로 선택한다. d 는 키의 개수 중 최소값이고, d+1 은 트리의 최소 차수(자식노드의 개수)의 최소값이 된다. 실제로 노드는 절반 이상의 키가 차있는 것이다.
내부노드가 가지고 있는 키의 개수가 0 ~ d-1 개일 수 없다는 뜻이다.
만약 내부노드가 2d 개의 키를 가지고 있는데 이 노드에 키가 추가된다고 하면, 이 노드를 d 개의 키를 가지는 2개의 노드로 분리하고, 2d+1 개의 키의 값들 중 중앙값을 골라서 부모노드의 키 중에서 적당한 중간에 위치시킨다. 각 분리된 d 개의 키를 가지는 2개의 노드는 최소로 가질 수 있는 키의 개수를 만족시킨다.
내부노드가 분리될 때 분리되는 기준값을 내부노드의 부모노드가 가지고 있어야 하기 때문에, 2d+1 개의 값 중 중앙값을 부모노드로 올리는 것이다.
비슷한 상황으로 만약 내부노드와 그 옆의 내부노드가 모두 d 개의 키를 가지고 있는데 내부노드에 1개의 키를 삭제하면 옆의 내부노드의 병합이 발생한다. 내부노드에는 d-1 개의 키를 가지고 있고, 합쳐지는 옆의 내부노드에는 d 개의 키를 가지고 있고, 노드 병합으로 인해 옆의 내부노드의 부모로부터 1개 키가 내려오게 된다. 그래서 결과적으로 병합된 내부노드는 꽉 차서 2d 개의 키를 가지고 있게 된다.
내부노드가 d 개의 키를 가지고 있는데 키가 삭제되면 d-1 개를 가지고 있게 되어서 B-tree 특성에 어긋나게 된다. 그래서 노드병합이 발생하는 것이다.
예를 들어 위의 그림에서 (9, 12) 를 가진 노드에서 12 를 삭제한다고 해보면, 오른쪽 노드와 병합되어서 (9, 18, 21) 의 값을 가지게 된다. 그런데 노드가 병합되기 때문에 부모노드의 키 중 16은 불필요하게 되므로 병합된 노드로 내려온다. 그래서 최종적으로 (9, 16, 18, 21) 의 값을 가지는 것이다.
한 노드의 자식노드의 개수는 노드에 저장된 키의 개수보다 1개 더 많다. 2-3 B-tree 에서는 내부노드는 1개 또는 2개의 키를 가지고 있어서 자식노드의 수가 2개 또는 3개만 가능하다. 이런 방식으로 B-tree 에서는 (d+1)-(2d+1) 또는 단순히 가장 높은 브랜칭 팩터(자식노드의 수)로서 (2d+1) 이라고 표현한다.
예를 들어 위의 그림에서는 한 노드에 키가 2~4개가 들어갈 수 있다. 그럼 자식노드의 수는 3~5가 될 수 있다. 이런 B-tree 를 3-5 B-tree 또는 5 B-tree 라고 표현한다.
B-tree 는 모든 리프노드가 같은 깊이를 가지고 있도록 균형된 상태를 유지한다. 이 트리의 깊이는 트리에 원소가 추가되는 속도에 비해 훨씬 천천히 늘어날 것이다. 트리의 깊이의 변화는 자주 있지 않지만, 이 변화는 리프노드가 루트노드로부터 한 노드를 더 거치게 만든다.
B-tree 는 데이터를 처리하는 횟수보다 조회하는 횟수가 매우 많을 때, 다른 구현방법에 비해 매우 큰 이점을 가지고 있다. 왜냐하면 조회에 드는 비용이 노드 내 복잡한 연산에 드는 비용을 상쇄시키기 때문이다. 이러한 상황은 보통 디스크 드라이브같은 외부 스토리지에 노드 데이터가 있을 때 많이 발생한다.
노드 조회 비용이 매우 작기 때문에 DML 로 인한 노드의 변화 연산을 상쇄시킬 수 있다는 뜻이다.
내부노드의 키의 개수를 늘릴 수록, 트리의 깊이가 낮아지고 노드 조회 횟수가 감소한다. 그리고 트리의 리밸런싱도 줄어들게 된다. 자식노드의 최대 개수는 저장될 데이터의 크기, 디스크 블럭의 크기 등으로 결정할 수 있다. 2-3 B-tree 는 설명하기 쉽지만, 실제로 사용하는 B-tree 는 성능 향상을 위해 많은 수의 자식노드를 가지도록 설계한다.
변종 알고리즘
B-tree 라는 용어는 정확히 어떤 한 가지 알고리즘을 나타내는 것일 수도 있고, 몇몇 변종을 포함한 모든 알고리즘을 나타내는 것일 수도 있다. 정확한 의미의 B-tree 는 내부노드에 키를 저장하기 때문에 리프노드에서 내부노드에 있는 키를 가지고 있을 필요가 없다. 모든 알고리즘을 포함하는 것으로 보면 변종 알고리즘(B+ tree, B* tree 같은 것들)까지로 볼 수도 있다.
- B+ tree 에서는 내부노드의 키가 복사되어서 리프노드가 그 키를 가지고 있다. 게다가 리프노드는 옆의 리프노드로 포인터도 가지고 있어서 부모를 거치지 않고 옆 리프노드로 접근할 수 있기 때문에 빠른 순차읽기가 가능하다.
- B* tree 는 이웃하는 내부노드들끼리 좀 더 키를 꽉 차게 가지고 있도록 균형을 맞춘다. 루트가 아닌 노드가 1/2 가 최소로 차 있는 것이 아니라 2/3 이 최소로 차 있도록 한다. 이 것을 유지하기 위해 내부노드가 가득 차면 분리시키면서, 분리된 노드들끼리 키를 공유해서 사용한다. 두 노드가 모두 가득찼으면 세 개의 노드로 분리된다. 키를 지우는 것은 넣는 것에 비해 다소 복잡하다.
- B-tree 는 older statistic tree 로서 사용할 수도 있다. N 번째 큰 키를 찾거나 2개 키 사이의 키의 개수를 찾거나 등등..
어원
Rudolf Bayer 와 Ed McCreight 는 B-tree 를 보잉 연구소에서 1971년도에 개발하였다. 그러나 그들은 B-tree 의 B 가 무엇을 의미하는지는 설명하지 않았다. Douglas Comer 는 아래와 같이 설명한다.
B-tree 의 기원은 저자에 의해 설명된 적이 한 번도 없다. 우리가 보건데 “balanced”, “broad” 또는 “bushy” 라고 생각이 된다. 다른 의견으로 “B” 가 보잉(Boeing)을 의미한다고 말하기도 한다. 그러나 B-tree 를 개발한 Rudolf Bayer 의 이름을 따서 “Bayer”-tree 라고 생각하는 것도 의미있을 것이다.
Donald Knuth 는 1980년도에 그의 강의인 “CS144C classroom lecture about disk storage and B-trees” 에서 “B” 는 보잉(Boeing) 또는 Bayer 의 이름에서 “B” 가 기원했을 것이라고 이야기했다.
Ed McCreight 는 2013년도에 B-tree 의 이름에 관한 질문에 대해 이렇게 대답했다.
Bayer 와 나는 이 트리의 이름에 관해 점심시간에 같이 생각하고 있었다. 그 B 는.. 음.. 우리는 당시에 보잉사에서 일하고 있었고, 변호사와의 상담 없이 그 이름을 쓸 수가 없었다. 그래서 B-tree 의 이름에 B 로 되어있는 것이다. B-tree 는 또한 균형잡혀(balanced) 있기 때문에 또 다른 B 도 있다. Bayer 는 당시 오래된 작가였다. 나보다 나이도 많았고, 출판물도 나보다 훨씬 많았다. 그래서 그의 이름인 Bayer 를 땄었고, 그 B 의 의미도 있다. 점심 테이블에서 이러한 B 의 의미들 중 어떤 것을 대표해서 B 로 할지 정하지 않았다. 그리고 실제로 이렇게 말했다. 당신이 B-tree 의 B 가 무엇을 의미하는지 생각할 수록, 당신은 B-tree 에 관해 더욱 잘 이해하게 될 것이라고.
데이터베이스와 B-tree
이 내용은 데이터베이스의 스토리지 엔진이 ISAM일 때를 고려해서 서술한 것 같다. 하지만 이런 스토리지 엔진은 사실 현재 거의 쓰이지 않기 때문에 참고만 하면 될 것 같다.
정렬된 데이터의 조회시간
아래 이야기들은 모두 데이터가 디스크에 정렬된 순서로 저장되어있는 상태에서 이야기하는 것이다.
보통 정렬과 조회 알고리즘은 Big O 노테이션을 사용해서 연산 횟수를 대충 계산하는 방법으로 평가된다. Binary search 는 N 개의 정렬된 데이터에 대해 대충 log2(N) 만큼 비교 연산을 해서 데이터를 찾을 수 있다. 만약 데이터가 총 1,000,000개가 있다면, 어림잡아서 log2(1000000) = 20 번 만큼의 연산을 통해 원하는 데이터를 찾을 수 있다는 뜻이다.
대용량의 데이터베이스는 일반적으로 데이터를 디스크 드라이브에 저장한다. 때문에 데이터를 읽는 시간이 데이터를 비교하는 시간보다 훨씬 더 오래 걸린다. 데이터를 디스크 드라이브에서 읽어오는 시간은 트랙 조회시간과 회전 조회시간으로 나누어진다. 트랙 조회시간은 0~20ms, 또는 그 이상 걸릴 수 있다. 그리고 평균적인 회전 조회시간은 회전주기의 절반이다. 예를 들어 7200 RPM 드라이브라면, 회전주기는 8.33ms 이고, 평균 회전 조회시간은 4.17ms 가 된다.
트랙 조회시간은 디스크에서 데이터를 찾기 위해 헤드가 트랙을 찾는 시간이다. 트랙을 찾은 뒤에는 원형으로 되어있는 트랙에서 데이터가 위치한 곳으로 이동해야 하는데, 그 시간이 회전 조회시간이다.
7200 RPM 은 1분마다 7200번 회전한다는 뜻이므로, 60*1000ms 마다 7200번 회전한다. 그러므로 60000/7200=8.33ms/rotation 이 계산된다. 그런데 회전 조회를 할 때는 헤드 위치에 데이터가 있을 수도 있고 한바퀴를 돌아야 데이터가 있을 수도 있으므로 이 절반 값인 4.17ms 가 평균 회전 조회시간이 되는 것이다.
Seagate ST3500320NS 디스크 드라이브 같은 경우, 트랙 조회시간은 0.8ms 정도이고, 평균 회전 조회시간은 8.5ms 이다. 단순하게 계산해서 데이터 조회시간은 10ms 가 걸린다고 계산하자.
대충 100만건 중 1건의 데이터를 찾는 시간이 20번 연산을 해야 한다고 위에서 계산했었다. 그런데 1번 디스크 드라이브로부터 데이터를 가져오는데 10ms 가 걸리기 때문에, 20*10ms=200ms=0.2s 가 걸리게 된다.
이 계산은 데이터를 비교하는 연산이 데이터를 가져오는 연산에 비해 시간이 매우 적게 걸린다고 위에서 가정했기 때문에, 데이터를 가져오는 시간만으로 계산해보는 것이다.
우리가 계산한 0.2s 라는 시간은 나쁘지 않다. 왜냐하면 각 데이터는 디스크 블럭에 그룹지어져서 있기 때문이다. 디스크 블럭은 보통 16Kbyte 이다. 만약 각 데이터가 160byte 라면, 1개 디스크 블럭에 100개의 데이터가 들어있는 것이다. 0.2s 라는 데이터 조회 시간은 이 100개의 데이터가 들어있는 디스크 블록을 읽는 시간이다.
그리고 한 번 디스크 헤드가 디스크 블록을 읽기 위해 자리를 잡았으면, 다음 데이터를 읽기 위해서는 헤드가 조금만 옆으로 가거나 바로 다음 트랙으로 가면 되기 때문에 읽어오는 시간이 거의 들지 않을 것이다.
한 디스크 블럭마다 100개의 데이터가 있는데, 비교연산 중에서 마지막 6번의 연산은 모두 1개의 디스크 블럭에 존재한다. 즉, 마지막 6번의 연산은 1번만 디스크 읽기가 발생한다는 것이다.
처음 1번의 디스크 조회로 100만개에서 50만개로 줄어든다. 2번째 디스크 조회로 25만개, 3번째 디스크로 12.5만개, 4번째.. 이렇게 하면 어느 순간부터는 조회하는 데이터 개수가 100개 이하로 될 때가 있을 것이다. 그 때가 마지막 6번째인 것이다.
그래서 조회 속도를 높이기 위해서는, 처음 13~14번의 비교연산(디스크 블럭 조회)가 빠르게 일어나게 만들면 된다.
인덱스를 통한 조회속도 향상
인덱스를 통해 엄청나게 조회속도를 향상시킬 수 있다. 위에서 예를 든 것처럼, 처음 디스크 읽기로부터 시작해서, 계속 읽어야할 데이터의 범위가 1/2로 줄어든다. 이 작업은 보조 인덱스를 만들어서 개선할 수 있다.
보조 인덱스는 각 디스크 블럭의 첫 데이터 값으로 만든다. (종종 이런 인덱스를 sparse index 라고 부른다.) 이 보조 인덱스는 원래 데이터베이스 크기의 1% 정도밖에 하지 않지만, 조회 속도를 빠르게 만들 수 있다.
이 보조 인덱스의 내용을 조회해서 데이터베이스의 어떤 블록을 읽어야할지 우리는 알 수 있게 된다. 보조 인덱스를 조회한 후, 우리는 데이터베이스의 딱 1개 디스크 블럭만 읽는다. 인덱스는 10,000개 데이터를 가지고 있고, 그래서 우리는 최대 14번의 비교 연산만 수행하게 된다.
위의 예를 계속 사용하는 것인데, 백만개 데이터가 있고 1개의 디스크 블럭에 백개의 데이터가 있으므로, 총 만개의 디스크 블록이 있다. 이 보조 인덱스는 각 디스크 블럭마다 1개의 값을 가지므로, 보조 인덱스에 만개 데이터가 존재한다. 그리고 연산 속도는 대략 log2(N) 이므로 최대 14번이라는 값이 나오게 된다.
데이터베이스와 비슷하게, 보조 인덱스도 디스크 드라이브에 저장되어 있다. 그러므로 같은 디스크 블럭에 보조 인덱스의 데이터도 있다. 그래서 마지막 6번의 연산은 1개 디스크 블럭에 모여있다. 그래서 보조 인덱스를 통해 데이터를 조회할 때 8번의 디스크 블럭 읽기, 그리고 1번의 원하는 데이터를 읽기 위한 디스크 블럭의 읽기가 발생해서 총 9번의 디스크 블럭 읽기가 발생한다.
보조 인덱스를 만드는 기법 중 하나는 보조 인덱스를 조회하기 위한 중첩된 보조 인덱스를 만드는 것이다. 이 것을 보조-보조 인덱스라고 부른다. 그리고 이 보조-보조 인덱스는 100개의 데이터만 있고, 이 데이터들은 모두 1개 디스크 블럭에 있을 것이다.
보조 인덱스가 위에 설명한 것처럼 만개의 데이터를 가지고 있다. 그리고 1개 디스크 블럭에 백개의 데이터를 가질 수 있으므로, 총 백개의 디스크 블럭에 저장되어 있다. 그러므로 보조-보조 인덱스는 백개의 디스크 블럭의 첫 데이터들로 만들기 때문에 백개의 데이터만 가지고 있는 것이다.
원하는 데이터를 찾기 위해 14번의 디스크 블럭 읽기 대신 우리는 3번의 디스크 블럭 읽기만 필요하다. 먼저 보조-보조 인덱스를 조회하기 위해 1개 디스크 블럭만 읽으면 모든 데이터를 읽을 수 있고, 여기서 보조 인덱스의 디스크 블럭 위치를 찾는다. 그리고 보조 인덱스에서 1번 디스크 블럭을 읽어서 데이터베이스의 디스크 블럭 위치를 찾는다. 다시 1번의 디스크 블럭을 읽어서 우리가 원하는 데이터를 찾을 수 있다. 150ms 대신, 우리는 딱 30ms 만으로 찾을 수 있게 된다.
우리는 원하는 데이터를 찾기 위해 binary search 문제로 해석해서 보조 인덱스도 비슷하게 속도가 걸릴 것이라고 생각했다. 즉 log2(N) 으로 해석했었다. 하지만 정확히는 logb(N) 만큼 필요하다. 여기서 b 는 블럭계수(1개 블럭에 얼마나 많은 데이터가 들어가는지, 여기서는 100 이므로 log100(1000000)=3 이 된다.)이다.
실제 적용할 때는, 만약 데이터베이스에 자주 조회가 발생한다면, 보조-보조 인덱스와 보조 인덱스들은 아마도 디스크 캐시에 올라와있을 것이기 때문에, 디스크 블럭 읽기가 많이 발생하지도 않는다.
삽입과 삭제
만약 데이터베이스가 변하지 않는다면, 인덱스를 구성하는 것은 매우 쉬운 일이다. 그리고 인덱스도 변하지 않는다. 만약 변한다면, 데이터베이스와 그 인덱스를 관리하는 일이 복잡해진다.
데이터베이스의 데이터를 삭제하는 것은 상대적으로 간단하다. 인덱스는 그대로 유지한 채, 데이터가 삭제되었다고 표시만 해두면 된다. 데이터베이스는 그래도 정렬된 채로 유지된다. 만약 수많은 삭제가 발생한다면 조회와 크기 면에서 비효율적이 될 것이다.
정렬된 데이터에서 삽입은 매우 느리다. 왜냐하면 삽입할 데이터를 위한 여유공간을 만들어야 하기 때문이다. 가장 작은 데이터가 들어올 경우 가장 앞에 데이터를 넣어야 하는데, 이 연산은 모든 기존 데이터를 한 칸씩 이동시켜야 한다. 이러한 연산은 실제 적용하기에는 너무 비싸다.
한 가지 해결방법은 여유공간을 미리 남겨두는 것이다. 디스크 블럭에 모든 데이터를 꽉 차게 넣어두는 대신, 디스크 블럭에 데이터 삽입이 일어날 수 있도록 어느정도 여유공간을 남겨둔다. 이런 여유공간은 마치 “삭제된” 데이터라고 표시해두는 것과 같다.
삽입과 삭제 모두 디스크 블럭에 여유공간이 있다면 상당히 빠르게 할 수 있다. 만약 데이터 삽입 시에 디스크 블럭에 맞지 않다면, 바로 근처의 빈 디스크 블럭을 찾아서 넣어야 하고, 인덱스를 변경시켜야 한다.
데이터베이스에서의 B-tree 장점
B-tree 는 위에 설명한 모든 아이디어들을 사용하고 있다.
- 키를 정렬된 순서로 유지해서 순차 조회가 가능하다.
- 디스크 블럭 읽기를 최소화하기 위해 계층구조의 인덱스를 사용한다.
- 빠른 삽입과 삭제 연산을 위해 일부 공간을 비워둘 수 있다.
- 재귀적인 알고리즘을 통해 항상 균형을 유지하고 있다.
게다가 B-tree 는 내부 노드가 최소한 반 이상은 차있도록 해서 빈 공간을 최소화하려고 노력한다. 그리고 B-tree 는 삽입과 정렬 연산도 처리할 수 있다.
기술적 설명
용어의 혼동
B-tree 에서 사용되는 용어는 통일된 의미를 가지고 있지 않다.
Bayer, McCreight, Comer 와 다른 사람들은 B-tree 의 차수를 내부노드가 가질 수 있는 키의 최소 개수로 정의했다. Folk, Zoellick 은 이렇게 차수를 정의하면 내부노드가 가질 수 있는 키의 최대 개수가 애매하다고 지적하였다. 예를 들어 3차 B-tree 는 최대로 가질 수 있는 키의 수가 6인지 7인지 확실하지 않기 때문이다. Knuth 는 이러한 문제를 피하기 위해 차수를 내부노드가 가질 수 있는 최대 자식노드의 수로 정의하였다.
리프에 대한 정의도 다르다. Bayer, McCreight 는 리프노드를 키를 가지는 노드들 중 가장 아래에 있는 것으로 생각했다. 하지만 Knuth 는 키를 가지는 가장 아래에 있는 노드의 자식노드들로 생각했다.
이러한 것들은 알고리즘 구현 과정의 선택이다. 어떠한 구현 디자인에서는 리프노드가 전체 데이터들을 가지고 있는 반면, 다른 구현 디자인에서 리프노드는 실제 데이터가 저장된 곳을 가르키는 포인터를 가지고 있다. 하지만 이러한 것들은 B-tree 알고리즘의 기본적인 것은 아니다. 단지 구현을 어떻게 할지의 차이일 뿐이다.
또한 k 라는 값을 어디서는 자식노드의 개수로 하고 어디서는 내부노드가 가지는 키의 개수로 쓰기 때문에 헷갈릴 여지가 있다.
단순하게 만들기 위해, 많은 저자들은 B-tree 를 설명할 때 노드를 채울 수 있는 키의 개수를 고정한다. 또한 키의 크기도 고정되어 있고, 그래서 노드의 크기도 고정되어 있다고 기본적으로 가정을 한다. 실제로는 가변적인 키의 크기를 사용할 수도 있다.
용어 정의
Knuth 의 정의에 따라, m 차 B-tree 는 아래의 속성들을 만족해야 한다.
- 모든 노드는 최대 m 개의 자식노드를 가질 수 있다.
- 모든 내부노드는 최소 ceil(m/2) 개의 자식노드를 가지고 있다.
- 루트노드는 만약 자신이 리프노드가 아니라면 최소한 2개의 자식노드를 가지고 있다.
- 리프노드가 아닌 노드에서 k-1 개의 키를 가지고 있다면, k 개의 자식노드를 가지고 있다.
- 모든 리프노드는 트리에서 같은 깊이에 존재한다.
각 내부노드의 키는 자식노드를 나누는 기준점으로서 동작한다. 예를 들어 내부노드에 3개의 자식노드가 있다면, 이 내부노드는 2개의 키(a1, a2)를 가지고 있다. 왼쪽에 있는 서브트리에 속한 모든 노드가 가지고 있는 키는 a1 보다 작은 값을 가지고 있다. 가운데 있는 서브트리에 속한 모든 노드에 속한 모든 노드가 가지고 있는 키는 a1 과 a2 사이에 있고, 오른쪽에 있는 서브트리에 속한 모든 노드가 가지고 있는 키는 a2 보다 큰 값을 가지고 있다.
- 내부노드
- 내부노드는 리프노드와 루트노드를 제외한 모든 노드를 말한다. 내부노드는 정렬된 키와 자식노드로의 포인터를 가지고 있다. 모든 내부노드는 최대 U 개의 자식노드를, 최소 L 개의 자식노드를 가지고 있다. 그래서 키의 개수는 자식노드의 개수보다 항상 1개 적다. (키의 개수는 L-1 개에서 U-1 개 까지 있을 수 있다.) U 는 반드시 2L 또는 2L-1 과 동일하다. 그러므로 모든 내부노드는 최소한 반은 차있다. U 와 L 의 관계는 2개의 반만 찬 노드들끼리의 합쳐서 정상적인 노드를 만들 수 있고, 꽉 찬 노드를 2개의 정상적인 노드로 분리될 수 있다는 것(부모노드에 분리되는 중앙값 1개를 넣을 공간이 있다면)을 암시한다. 이러한 속성들은 B-tree 에 삽입과 삭제 연산을 가능하게 한다.
- 루트노드
- 루트노드의 자식노드 최대 개수 제한은 내부노드와 동일하지만, 최소 개수 제한은 없다. 예를 들어 L-1 개 보다 적은 개수의 키를 가지고 있어도 괜찮다.
- 리프노드
- 리프노드는 내부노드와 동일한 제약을 가지고 있지만, 자식노드가 없다는 것만 다르다. 자식노드로의 포인터가 아예 없다.
n+1 깊이의 B-tree 는 n 깊이의 B-tree 보다 최대 U 배 만큼의 데이터를 더 가지고 있을 수 있지만, 조회/삽입/삭제 연산의 비용도 증가하게 된다. 하지만 다른 balanced tree 와 비슷하게 데이터의 수에 비해서 연산의 비용의 증가속도는 매우 느리다.
어떤 balanced tree 는 리프노드에서만 데이터를 가지고 있기도 하고, 내부노드와 리프노드를 아예 다른 종류로 생각하기도 한다. B-tree 는 트리 내 모든 노드에서 데이터를 가지고 있고, 모든 노드가 동일한 구조를 가지고 있다.
최선, 최악 경우의 트리 높이
h 를 기본적인 B-tree 의 높이이고, n 은 트리에 있는 키의 개수이다. m 은 노드가 가질 수 있는 최대 자식노드의 개수이다. 즉, 노드는 최대 m-1 개의 키를 가질 수 있다.
높이가 h 인 B-tree 의 노드가 모두 m-1 개의 키로 가득차 있는 경우, n=m^(h+1)-1 의 식이 성립한다. 그래서 최선의 경우 B-tree 의 높이는 ceil(logm(n+1))-1 로 정의할 수 있다.
꽉 찬 B-tree 에서 높이가 1 인 경우, 루트노드에 m-1 개, 자식노드가 총 m 개에 자식노드마다 m-1 개를 가지고 있으므로 총 m-1+m(m-1) 개가 된다. 높이가 2 인 경우는 루트노드에 m-1 개, 1차 자식노드에 m(m-1) 개, 2차 자식노드에 m^2(m-1) 개이다. 그래서 m-1+m(m-1)+m^2(m-1) 개가 된다. 일반화하면 높이가 h 인 경우 전체 키의 개수는 (m-1)(1+m+m^2+..+m^h=m^(h+1)-1 이 되는 것이다.
d 를 내부노드가 가지는 최소 자식 노드의 개수라고 하자. 그렇다면 d=ceil(m/2) 이다.
Comer, Cormen 은 최악의 경우의 높이는 아래와 같다고 하였다.
h<=floor(logd((n+1)/2))
알고리즘
조회
조회는 binary search tree 의 조회과정과 비슷하다. 루트노드부터 시작해서, 트리는 재귀적으로 위에서부터 아래로 원하는 데이터를 찾아나간다. 각 단계의 조회마다 조회해야할 범위가 감소된다.
노드에서 원하는 값을 찾을 때 Binary search 를 보통 사용한다. (꼭 필요한 것은 아니다.)
어떤 내부노드에 (1, 3, 7, 10) 처럼 4개의 키가 있는데, 5 라는 데이터를 찾기 위해서 앞에서부터 하나하나 비교해서 자식노드를 찾을 수도 있고, binary search 를 사용해서 찾을 수도 있다는 뜻이다.
삽입
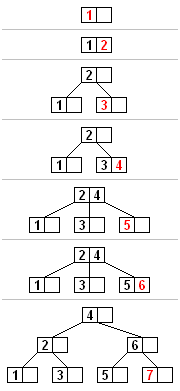
모든 삽입은 리프노드부터 시작한다. 새로운 데이터를 넣기 위해서 우선 새로운 데이터가 어떤 리프노드에 들어가야할지 찾는다. 새로운 데이터를 찾은 리프노드에 넣고 아래의 작업들이 순서대로 일어난다.
- 만약 리프노드가 허용되는 최대개수의 키를 가지고 있지 않다면 빈 공간이 있다는 뜻이다. 리프노드에 새로운 데이터를 정렬상태를 유지하도록 적당한 위치에 넣는다.
- 만약 리프노드가 가득 차있다면, 아래와 같이 노드 분리가 일어난다.
- 새로운 데이터를 포함해서 노드에 있는 키 중 1개의 중앙값을 선택한다.
- 중앙값보다 작은 키는 왼쪽 리프노드를 만들어서 넣고, 중앙값보다 큰 키는 오른쪽 리프노드로 만들어서 넣는다. 중앙값은 키의 분리 기준이 된다.
- 중앙값은 리프노드의 부모노드로 삽입한다. 만약 부모노드가 가득 차있다면 위의 과정이 재귀적으로 일어난다. 만약 부모노드의 부모가 없다면(즉, 루트노드라면) 새로운 루트노드를 만든다. (트리의 깊이가 늘어나게 된다.)
위 그림에서 4번째 트리 상태에서 5가 새로 입력된다고 하자. 그럼 오른쪽 리프노드는 (3, 4, 5) 의 데이터를 가지고 있고, 최대 2개의 키만 가질 수 있기 때문에 노드 분리가 일어난다. 4가 중앙값이 되고, 3은 왼쪽 노드로, 5는 오른쪽 노드로 분리된다. 4는 부모노드로 이동해서 부모노드는 (2, 4)의 값을 가지게 된다. 부모노드는 최대로 가질 수 있는 키의 개수를 넘지 않으므로 재귀작업이 바로 종료되게 된다.
그 다음에 7이 입력되는 상황을 살펴보면, 오른쪽 리프노드에 (5, 6, 7) 의 키가 저장되게 되므로 분리가 일어난다. 중앙값 6은 부모노드로, 5는 왼쪽 노드로, 7은 오른쪽 노드로 분리된다. 그런데 부모노드가 6의 데이터를 저장하게 되면 (2, 4, 6)의 키를 가지고 있으므로 재귀적으로 노드 분리가 일어난다. 마침 이 노드는 트리의 루트노드이기 때문에, 중앙값을 새로운 루트노드를 만들어서 올리게 되므로, 새로운 루트노드는 4의 키만 가지게 된다. 2는 새로운 루트노드의 왼쪽노드로, 6은 오른쪽 노드로 분리된다.
만약 노드 분리가 루트노드노드까지 올라가게 된다면, 기존 루트의 중앙값을 가지고 새로운 루트노드를 생성하게 되고, 기존 루트노드가 2개의 내부노드로 분리된다. 이 작업 때문에 루트노드는 내부노드가 가지는 키의 개수의 최소 제한을 가지지 않는다. 노드마다 최대 키의 개수는 U-1 이다. 노드가 분리될 때, 1개의 키는 부모노드로 이동하면서 1개의 키가 추가된다. 그래서 키의 최대 개수인 U-1 을 가지는 노드가 정상적인 2개의 노드로 분리될 수 있는 것이다. 만약 이 수가 홀수라면, U=2L 이고 분리되어 새로 생기는 노드 중 1개는 (U-2)/2=L-1 개의 키를 가지게 되므로 정상적이다. 다른 1개의 노드는 1개의 키를 더 가지고 있기 때문에 마찬가지로 정상적이다. 만약 U-1 이 짝수라면 U=2L-1 이고, 그러므로 2L-2 개의 키가 노드에 있다. 이 절반은 L-1 이고, 분리되는 노드들이 가질 수 있는 최소개수이므로 또한 정상적이다.
개선된 알고리즘은 새로운 데이터 삽입 시에 루트부터 노드까지 한 번 훑고 지나가면서 만나는 가득 찬 노드들을 분리시킨다. 이 방법은 부모노드가 메모리로 계속 호출되는 것을 방지해서, 트리가 외부 스토리지에 있을 때 비싼 디스크 리드 작업을 줄여준다. 그러나 개선된 알고리즘을 사용하기 위해서 새로운 키를 추가하지 않은 채 1개 키를 부모로 보내고 남은 U-2 개의 키를 2개로 분리시킬 수 있어야 한다. 그래서 U=2L-1 보다 U=2L 인 상태를 필요로한다. 이 것이 왜 교과서에서 B-tree 를 정의할 때 U 가 홀수인지 설명해준다.
개선된 알고리즘이 어떤 것인지는 추가적인 링크나 설명이 없어서 뭔지 모르겠다.
삭제
B-tree 에서 키를 삭제하는 연산에는 2가지 대표적인 방법이 있다.
- 키가 위치한 곳을 찾아서 키를 지우고, 이 변화를 반영해서 전체 트리를 재구성한다.
- 트리를 루트노드에서부터 훑고 내려간다. 그런데 실제 노드를 방문하기 전에 트리를 재구성하도록 한다. 그래서 지울 키를 만났을 때 키를 지우더라도 추가적인 트리 재구성이 일어나지 않도록 한다.
다만 키 삭제 시에 아래 2가지 상황을 고려해야 한다.
- 내부노드의 키는 자식노드의 분리기준이 된다.
- 키를 지울 때 노드가 가져야할 최소 키의 개수를 유지해야 한다.
이런 조건들을 만족하기 위해 아래의 작업들이 순서대로 일어난다.
리프노드에서 삭제
- 삭제할 데이터를 찾는다.
- 만약 이 데이터가 리프노드에 있다면, 그냥 리프노드의 데이터를 지운다.
- 만약 데이터를 지워서 노드가 가져야할 최소 키의 개수를 만족시키지 못하게 되면, 아래 있는 삭제 후 재구성 작업을 거친다.
내부노드에서 삭제
내부노드의 각 키는 2개의 서브트리를 구분하는 기준값이다. 그러므로 우리는 구분을 대체할 새로운 무언가를 찾아야 한다. 왼쪽 서브트리의 가장 큰 값도 이 구분값보다는 작다는 것을 기억하자. 비슷하게 오른쪽 서브트리의 가장 작은 값도 이 구분값보다는 크다. 데이터를 삭제할 내부노드가 리프노드 바로 위에 있다고 생각하면 아래 작업들을 통해 삭제 작업이 일어난다. (내부노드가 리프노드 바로 위에 있지 않아도 아래 작업이 재귀적으로 일어난다.)
- 내부노드에서 키가 1개 삭제되었으므로, 1개의 새로운 구분 기준값을 선택한다. 이 구분 기준값은 왼쪽 서브트리에서 가장 큰 값, 또는 오른쪽 서브트리에서 가장 작은 값을 선택할 수 있다. 선택한 구분 기준값을 리프노드에서 지우고, 삭제된 키와 선택한 구분 기준값을 교체한다.
- 이전 스텝에서 리프노드에서 키 1개를 삭제했다. 이 리프노드가 만약 불안전해졌다면(즉, 최소 키의 개수 조건을 지키지 못하게 됐다면), 아래 있는 삭제 후 재구성 작업을 거친다.
삭제 후 재구성
재구성 작업은 리프노드로부터 루트노드까지 진행되며, 트리가 균형 상태를 유지할 때 중지된다. 만약 데이터의 삭제가 노드의 최소 크기 미만으로 키를 가지게 만들었다면, 일부 데이터들은 반드시 재분배되어서 모든 노드가 최소 크기 조건을 지키도록 만들어야 한다. 보통 재분배는 키의 최소 개수보다 많이 가지고 있는 형제노드에서 부족한 노드로 키를 이동시킨다. 이러한 재분배 연산 방법을 키의 순환이라고 부른다. 만약 형제노드들 중 어떤 노드도 여분의 키가 없다면, 키를 부족하게 가지고 있는 노드는 형제노드와 병합되어야 한다. 병합 과정은 부모노드에서 분리기준이 되는 키가 없어져야 하는 것을 말한다. 그래서 부모노드는 키 부족을 겪을 수 있고, 다시 재구성이 필요해진다. 이러한 병합과 재구성은 루트까지 계속해서 일어난다. 키의 최소 개수 조건은 루트에 적용되지 않기 때문에, 루트는 키 부족 현상을 겪지 않는다. 재구성 알고리즘은 아래와 같이 동작한다.
- 만약 키 부족 노드에 오른쪽 형제노드가 있고, 이 형제노드가 최소 개수 초과의 키를 가지고 있다면 왼쪽으로의 키 순환이 발생한다.
- 부모노드로부터 키 부족 노드를 분리시키는 분리 기준값을 가지고 와서, 키 부족 노드에 넣는다. (기준값이 아래로 내려오고, 키 부족 노드는 최소 키 개수를 만족시키게 된다.)
- 부모노드의 분리 기준값을 오른쪽 형제노드의 첫 번째 키로 대체한다. (오른쪽 형제노드는 1개의 키를 읽게 되지만, 최소 키 개수를 만족시킨다.)
- 이제 트리는 균형 상태를 유지하게 된다.
- 만약 키 부족 노드에 왼쪽 형제노드가 있고, 이 형제노드가 최소 개수 초과의 키를 가지고 있다면 오른쪽으로의 키 순환이 발생한다.
- 부모노드로부터 키 부족 노드를 분리시키는 분리 기준값을 가지고 와서, 키 부족 노드에 넣는다. (기준값이 아래로 내려오고, 키 부족 노드는 최소 키 개수를 만족시키게 된다.)
- 부모노드의 분리 기준값을 왼쪽 형제노드의 마지막 키로 대체한다. (왼쪽 형제노드는 1개의 키를 잃게 되지만, 최소 키 개수를 만족시킨다.)
- 이제 트리는 균형 상태를 유지하게 된다.
- 키 부족 노드의 왼쪽 오른쪽 형제노드가 모두 최소 개수의 키만 가지고 있다면, 부모노드로부터 분리 기준값을 가지고 와서 형제노드와의 병합 과정이 일어난다.
- 분리 기준값을 왼쪽 노드의 마지막으로 복사한다. (왼쪽 노드는 키 부족 노드일 수도 있고, 최소 개수의 키를 가지고 있는 노드일 수도 있다.)
- 오른쪽 노드로부터 모든 값을 왼쪽 노드로 이동시킨다. (왼쪽 노드는 이제 가질 수 있는 최대 개수의 키를 가지고 있을 것이고, 오른쪽 노드는 비어있을 것이다.)
- 만약 부모노드가 루트노드이고 아무런 키도 가지고 있지 않다면, 이 노드를 제거하고 남은 노드를 루트노드와 병합해서 새로운 루트노드로 만든다. (트리의 깊이가 낮아진다.)
- 그렇지 않다면, 부모노드가 필요한 최소 개수의 키보다 적어진다면, 부모노드로부터 다시 재구성 작업을 시작한다.
순차접근
처음 데이터베이스가 구동되었을 때는 순차접근에 대해 좋은 성능을 보이는 반면, 데이터베이스가 커짐에 따라 순차접근이 점점 어려워져서 랜덤 I/O 와 성능 면에서 안좋아진다.
최초 구성
어플리케이션의 입장에서는 B-tree 를 만들어서 대용량의 데이터를 저장하고 B-tree 의 연산을 사용해서 데이터를 업데이트 시키는 것은 매우 유용하게 쓰일 수 있다. 이런 경우, 가장 효율적인 최초 B-tree 구성 방법은 데이터를 계속해서 집어넣는 것이 아니다. 그 대신 입력할 데이터로부터 최초 리프노드를 미리 구성한 뒤에 그 리프노드로부터 내부노드를 구성하는 것이 좋다. 이런 방식의 B-tree 구성방법을 벌크로딩이라고 한다.
처음에는 모든 리프노드에 가질 수 있는 최대 키의 개수보다 1개씩 더해서 만든다. (더해지는 1개는 내부노드 구성을 위해 쓰일 것이다.) 예를 들어 1~24의 정수로 최대 키의 개수가 4개인 B-tree 를 구성한다고 하자. 그러면 4개보다 1개 많은 5개로 리프노드를 구성한다. 마지막 리프노드는 4개만 들어가게 된다.

마지막 리프노드만 제외하고 나머지 리프노드에서 마지막 값을 선택해서 부모 내부노드를 만들기 위해 키를 올린다. 위의 예에서 내부노드는 최대 2개의 키(3개의 자식노드)를 가질 수 있다고 가정하자. 그래서 아래와 같이 될 것이다.

이 과정은 리프노드에서부터 재귀적으로 진행되어 1개의 노드만 남을 때까지 진행된다. 위의 예를 끝까지 진행하면 아래처럼 진행되어 완료된다.

위의 예에서 리프노드는 최대 4개의 키를 가지는데, 내부노드는 최대 2개의 키를 가지도록 가정하면서 진행했다. B-tree 의 알고리즘은 내부노드의 관계에 관해 설명하는 것이 중심이고, 리프노드의 개수나 데이터 종류 등은 개요 부분에서 설명한 것처럼 구현 상의 문제인 것이다. 그래서 여기에서 예시로서 키의 개수가 다른 경우도 설명한 것 같다.
파일시스템과 B-tree
데이터베이스에서 더해서, B-tree(또는 그 변종 알고리즘) 가 특정 파일의 디스크 블럭을 찾아서 접근하기 위해 파일시스템에 사용된다. 파일시스템의 가장 기본적인 문제는 파일 블럭 i 의 주소를 디스크 블럭 주소(또는 실린더 헤드 섹터)로 매핑하는 것이다.
어떤 운영체제들은 파일을 생성할 때 생성하는 사용자에게 파일의 최대 크기를 할당하게 한다. 그러면 파일은 최대 크기에 맞게 연속된 디스크 블럭에 위치시킬 수 있고, 운영체제는 단순히 파일 블럭 주소 i 에 첫 번째 디스크 블럭의 주소만 매핑시켜두면 된다. 이 방법은 매우 단순하지만, 파일이 처음 지정한 최대 크기를 넘을 수 없게 된다.
다른 운영체제에서는 파일이 점점 커져가는 것을 허용한다. 이 말은 파일이 저장되는 디스크 블럭이 연속해서 존재하지 않는다는 뜻이고, 그래서 논리적 블럭(파일 블럭)을 물리적 블럭으로 매핑하는 작업이 필요하다.
예를 들어 MS-DOS 운영체제는 단순한 File Allocation Table(FAT) 를 사용했다. FAT 는 각 디스크 블럭의 데이터 리스트를 가지고 있고, 이 데이터 리스트는 파일이 어떤 블럭에 위치하는지 알고 있다. 그리고 어떤 파일이 어느 블럭에 있고, 이 블럭 다음의 블럭은 무엇인지 알고 있다. 그래서 각 파일의 블럭 할당은 테이블 내의 링크드리스트로 표현된다. 파일 블럭 i 의 디스크 주소를 찾기 위해, 운영체제(또는 디스크 유틸리티)는 FAT 안에 있는 파일의 디스크 블럭 링크드리스트를 순서대로 쫓아가야 한다. 더 안좋은 점은, 빈 디스크 블럭을 찾기 위해서 반드시 FAT 를 순서대로 스캔해보아야 한다는 것이다. 이런 점은 MS-DOS 운영체제에 큰 단점은 아니었는데, 왜냐하면 디스크와 파일의 크기가 (현재에 비하면) 작아서 데이터 리스트가 작았기 때문이다. FAT12 파일시스템(플로피디스크와 초기 하드디스크에 쓰이던)은 4080개 이상의 데이터 리스트가 있을 수 없었다. 그리고 FAT 는 주로 메모리에 상주해있다. 디스크가 점점 커지면서 FAT 구조는 큰 결점을 가지게 된 것이다. FAT 를 사용하는 큰 디스크는 파일 블록의 위치를 확인하기 위해 링크드리스트를 모두 읽어야 하기 때문이다.
Apple 의 파일시스템은 HFS+, Microsoft 는 NTFS, AIX (jfs2) 그리고 일부 Linux 는 btrfs 나 ext4 를 사용한다. 모두 B-tree 를 사용하는 것들이다.
B*-tree 는 HFS 와 Reiser4 파일시스템에 사용된다.
변종
동시 접근
Lehman 과 Yao 는 트리에서 다음 형제블럭을 가르키는 포인터가 있다면 읽기 잠금을 회피할 수 있는 것을 증명했다. (이로서 동시 접근성이 엄청나게 향상된다.) 이 것은 루트노드와 리프노드로 삽입과 조회 연산이 내려오는 트리연산에 영향을 끼친다. 쓰기 잠금은 트리 블럭이 수정될 때만 필요하다. 여러 사용자들로부터 동시 접근을 최대로 할 수 있으려면, ISAM 스토리지 엔진을 기반으로한 B-tree 또는 데이터베이스로부터의 고려가 필요하다. 이런 향상의 트레이드 오프로서 빈 페이지는 B-tree 에서 제거될 수 없다는 것이 있다. (그러나 노드 병합 등의 다른 방법이 있긴 하다.)
1994년도에 등록된 미국 특허 5283894 에서 메타 접근 방법 이라는 방식이 나타난다. 이 것은 B+ tree 의 동시 접근을 허용하면서 잠금 없이 수정할 수도 있다. 이 기법은 메모리에 별도의 인덱스(트리의 깊이마다 어떤 블럭에 있는지 가르키는 인덱스)를 만들고, 이 인덱스를 활용해서 트리의 조회와 변경을 아래(리프노드)에서 위(루트노드)로 접근하는 방식을 취한다. 삭제 연산을 할 때도 재구성이 필요없고, 각 블럭마다 다음을 가르키는 포인터도 없다.