
RAID 에 대해 알아보기
데이터베이스를 구성할 때 가장 중요한 부분이 디스크가 아닐까 싶다. 결국 데이터가 저장되는 곳이 디스크이기도 하고, 많은 경우에 디스크 I/O 로 인한 성능의 병목이 일어나기 때문이다. 그래서 디스크 구성을 어떻게 할지가 중요하다.
각 데이터베이스 별로 추천하는(?) 디스크 구성들이 있다. Elasticsearch 는 RAID 0 으로, MongoDB 는 RAID 1+0 을 추천한다. (물론 이것만 해야되는 건 아니다.) 그래서 RAID 를 알아야 한다.
RAID 는 Redundant Array of Independent Disks 혹은 Redundant Array of Inexpensive Disks 의 약자이다. 여러 개의 디스크에 하나의 디스크처럼 쓰는 방법이다. 외부에서 볼 때는 하나의 디스크처럼 쓰지만, 내부에서는 그 데이터를 나누어서 저장한다. 데이터를 나누어서 저장하는 방법은 레벨에 따라서 다른데, 그 방법에 따라서 읽고 쓰는 속도가 높아지기도 하고 안정성이 높아지기도 한다.
HW RAID, SW RAID
RAID 는 크게 HW RAID 와 SW RAID 2가지로 나눌 수 있다.
HW RAID
HW RAID 는 CPU 와 메모리를 가지는 별도의 디스크 컨트롤러에 디스크를 꼽아두고, 이 컨트롤러가 데이터를 나누어서 저장하는 것을 말한다.
각 벤더별로 상세한 기술들은 다르지만, 대체로 SW RAID 보다 안정적이고 성능이 좋다. 또한 OS 입장에서는 RAID 로 묶인 최종 디스크들만 인식할 수 있기 때문에 RAID 에 관해서 신경쓰지 않아도 되므로 편하다.
SW RAID
SW RAID 는 비싼 HW RAID 의 대체안으로서 OS 의 SW 에서 데이터를 나누어서 저장하는 방식을 말한다. Linux 는 mdadm 명령어를 통해 수행할 수 있다.
HW 로 하느냐 SW 로 하느냐만 다를 뿐, 실제 데이터의 분산과 RAID 레벨 별 특징은 동일하다.
RAID Level
보통 RAID 를 구성하는 디스크들은 모두 같은 벤더의 같은 제품, 같은 크기들로 구성한다. 아래 내용들 모두 디스크의 크기가 같다고 가정하자.
RAID 0
RAID 0 는 아래 그림처럼 디스크들에 넣어야할 데이터들을 병렬로 나누어서 동시에 저장한다. 이런 저장방식을 Striping 이라고 한다.
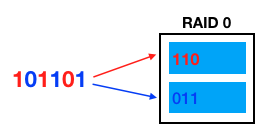
여기서 동시에 저장한다는 말은 데이터를 순서대로 나누어서 2개 디스크로 저장한다는 뜻이다. 즉 1개 디스크에 저장하는 것 보다 병렬로 저장하므로 저장 속도가 약 2배가 된다. (물론 이런저런 이유로 실제 2배는 아니다.)
3개 디스크를 RAID 0 으로 묶으면 3배, 4개 디스크면 4배 가까이 될 것이다.
쓰기 속도와 읽기 속도는 약 2배 가량 되서 성능상 엄청난 이점이 있지만, 만약 2개 중 1개라도 디스크가 고장난다면 디스크 내의 모든 데이터를 읽어버리게 된다. 1개 디스크에 있는 내용만으로 원래 내용을 알 수 없기 때문이다. 즉, 빠르게 읽고 써야 하지만 잃어버려도 상관없는 데이터라면 RAID 0 이 적절하다.
전체 용량은 RAID 로 묶인 전체 디스크 용량의 합과 같다.
RAID 1
RAID 1 은 아래 그림처럼 디스크들에 넣어야할 데이터를 2개로 복사해서 저장한다. 이런 저장방식을 Mirroring 이라고 한다.
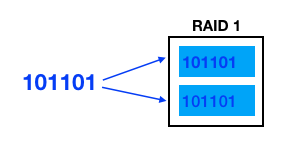
디스크를 3개, 4개를 써서 RAID 로 그룹을 묶을 수 있다. (그런데 실무에서 2개까지는 RAID 1 으로 묶어도 3개 이상을 묶는 경우는 못봤다.) 그리고 많은 디스크를 묶을 수록 안정성이 높아진다. 디스크가 1개가 고장나도 다른 디스크에 모든 데이터가 있기 때문이다. 이렇기 때문에 데이터를 절대 잃어버려서는 안된다면 RAID 1 로 구성하는 것이 적절하다.
다만 이 구성은 디스크를 많이 필요로 한다. 같은 데이터를 저장하는 용도로 여러 디스크를 사용하기 때문이다.
전체 용량은 RAID 로 묶인 디스크들 중 1개의 디스크 용량과 같다.
RAID 1 로 데이터가 복제된다고 해서 데이터의 백업이 필요없는 것은 아니다. 물론 데이터가 복제되면 이 것으로 백업 데이터라고도 할 수 있다. 하지만 이 것은 사용자의 실수로 인해 데이터가 지워진 경우는 보장할 수 없다. 즉, Point In Time Recovery 가 불가능한 것이다. 단지 Availability 를 보장할 뿐이므로 데이터 백업은 별개로 생각해야 한다.
RAID 2, RAID 3, RAID 4
위에서 본 것 처럼 RAID 0 은 디스크 오류에 따라 데이터가 유실되기 쉬운 반면, RAID 1 은 데이터를 저장하기 위해 많은 디스크를 사용한다.
그래서 RAID 2~4 는 이 중간 어디쯤의 안정성과 효율성을 가지기 위해 오류정정부호 를 사용한다. RAID 레벨 별로 오류정정부호를 계산하는 방법이 다를 뿐 구성은 전부 아래와 같이 동일하다.
오류정정부호는 데이터의 비트 중 오류가 있다면, 그 오류를 찾아내서 원래 비트로 복구를 시킬 수 있는 추가데이터를 말한다. 물론 100% 오류 비트를 찾아서 복구할 수 있는 것은 아니다.
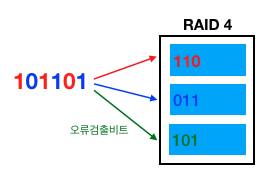
들어오는 데이터의 일정 비트를 묶고, 오류정정부호를 계산해서 추가 데이터를 1개 디스크에 몰아서 저장한다. 이와 같은 경우 1개 디스크에 오류가 생겨도 오류정정부호를 통해 없어진 디스크의 내용을 유추해낼 수 있기 때문에 어느정도 디스크 오류에 따른 안정성도 가지고 있고, 또한 데이터를 병렬 저장하기 때문에 저장 속도도 높다.
전체 용량은 RAID 로 묶인 디스크들 중 1개를 빼고 나머지 디스크들 용량의 합과 같다.
하지만 현재 RAID 2~4 는 거의 쓰이지 않는다고 한다. 오류정정부호를 저장하는 디스크에 입출력에 따른 병목 현상이 발생해서 이 디스크의 수명이 다른 디스크에 비해 짧아지기 때문이다.
주로 이 방법을 개선한 RAID 5 가 많이 쓰인다.
RAID 5
RAID 5 는 RAID 2~4 와 거의 동일하다. 오류정정부호로 Parity Bit 을 써서 계산을 단순화하고, 이 데이터를 1개의 전담 디스크에 저장하는 것이 아니라 분산시켜서 저장한다. 이 방법으로 RAID 2~4 의 단점을 개선시켰다.
Parity Bit 은 오류 또는 유실 비트를 복구하기 위해 별도로 저장하는 Bit 이다. 예를 들어 2 bit 의 데이터를 저장할 때마다 1 bit 의 Parity Bit 을 같이 저장한다. Parity Bit 을 만드는 방법은 전체 비트의 합을 홀수로 만들거나 또는 짝수로 만들거나, 2가지가 있다. 예로 Parity Bit 은 항상 합이 짝수가 되도록 한다고 하자. 그러면 11 데이터가 들어오면 Parity Bit 을 0 으로 설정해서 110 으로 저장하는 것이다.
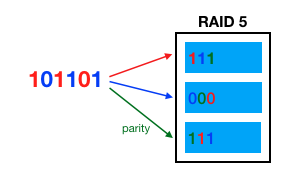
RAID 5 의 장점은 1개 디스크 까지는 오류가 생겨도 복구가 가능하며, 저장 공간도 1개 디스크 빼고 나머지 디스크는 모두 활용할 수 있으므로 좋다. 저장속도 또한 1개 디스크 빼고 나머지로 병렬 저장되므로 괜찮게 나온다. 더 많은 디스크를 RAID 5 로 구성할 수록 효율성이 높아진다.
다만 쓰기 작업 시 Parity Bit 을 계산해야 하고, 디스크 에러 시에는 읽기 작업 시에도 Parity Bit 을 계산해야 하므로 CPU 와 Memory 를 더 사용할 수 있다.
실제 RAID 5 로 많은 디스크를 묶으면 문제가 생기는 확률이 높아진다고 한다. 여기 를 참고해보자.
RAID 6
RAID 6 은 RAID 5 보다 안정성을 높이기 위해 Parity Bit 을 2개 만들어서 저장하는 것이다. 그러므로 최소 4개 이상의 디스크가 필요하고, 그 중 2개 디스크 만큼의 용량은 Parity Bit 을 저장하는데 사용된다.
RAID 5 는 1개 디스크에 오류가 발생해도 견딜 수 있고, RAID 6 는 2개 디스크에 오류가 발생해도 견딜 수 있다.
Nested RAID Level
위에서 알아본 것이 기본적인 RAID 의 레벨이다. 그런데 RAID 는 이런 레벨들을 중첩시켜서 사용할 수 있다.
RAID 로 묶은 디스크 그룹은 결국 OS 가 보기에는 1개의 디스크로 보인다. 그래서 이런 디스크들은 다른 RAID 로 다시 묶을 수 있는 것이다.
그래서 RAID 1+0, RAID 0+1, RAID 0+6 등등 많은 조합들이 생길 수 있는데, 그 중에 RAID 1+0 이 많이 사용되는 것 같다.
RAID x+y 에서 RAID x 가 먼저 디스크에 적용되고, 이것으로 만들어진 디스크들에 대해 RAID y 가 적용된다.
RAID 1+0, RAID 0+1
RAID 1+0 은 디스크들을 먼저 RAID 1 로 묶고, 이런 디스크 그룹들을 RAID 0 으로 묶는 것을 말한다. 그러므로 최소 4개 이상의 디스크가 필요하다. 아래 그림을 보자.
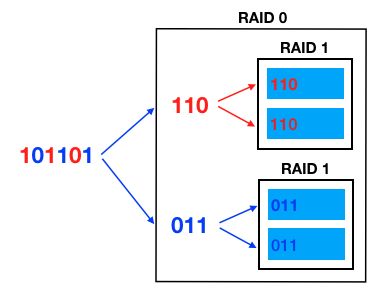
데이터가 들어오면 Stripping 되고, 나누어진 데이터들이 Mirroring 되어서 디스크에 저장된다.
반대로 RAID 0+1 은 디스크들을 먼저 RAID 0 으로 묶고, 이런 디스크 그룹들을 RAID 1 로 묶는 것을 말한다.
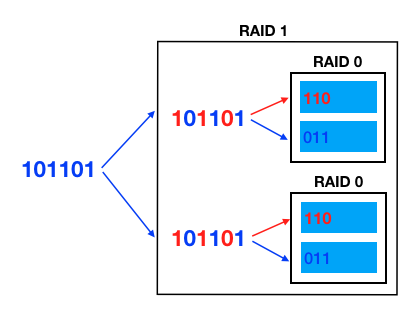
데이터가 들어오면 Mirroring 되고, 복사된 데이터들을 Stripping 해서 저장된다.
디스크가 4개일 때는 RAID 1+0 이나 RAID 0+1 이나 동일하다. 그러면 디스크 오류 관련되서 생각해보자.
RAID 1+0 에서 (위에서부터) 첫 번째 디스크가 오류가 발생했어도 정상 동작한다. RAID 1 로 묶여 있기 때문이다. 그런데 거기에서 두 번째 디스크까지 오류가 발생했으면? RAID 0 의 첫 번째 디스크그룹(첫 번째, 두 번째 디스크)에서 데이터를 읽을 수 없기 때문에 RAID 1+0 은 깨지게 된다. 다만 첫 번째, 세 번째 디스크가 깨지는 것은 괜찮다.
즉, RAID 1+0 은 RAID 1 로 묶인 디스크들 중 1개만이라도 살아있을 때 까지 디스크 오류가 있어도 괜찮다.
RAID 0+1 에서 첫 번째 디스크와 두 번째 디스크가 오류가 났다면? 세 번째, 네 번째 디스크에서 데이터를 읽을 수 있기 때문에 오류가 나지 않는다. 대신 첫 번째와 세 번쨰 디스크가 깨진다면 RAID 0+1 은 깨진다.
즉, RAID 0+1 은 RAID 1 로 묶인 디스크그룹들 중 1개의 디스크그룹을 뺀 나머지는 모두 디스크 오류가 있어도 괜찮다.
다음은?
RAID 만들어보기 로 직접 RAID 를 구성해보자.